Este artículo me lo han pedido muchísimos programadores de Clipper, y hasta ahora había tenido tiempo de escribirlo con calma, de hecho me ha llevado poco mas de una semana.
Lo que explicaré a continuación es la forma fácil y rápida de migrar tus programas CA-Clipper a (x)Harbour, con las menores molestias posibles, utilizando una herramienta muy interesante : XEDIT.
XEdit es una herramienta hecha en Xailer, de hecho, XEdit es un buen ejemplo de lo que se puede lograr programando con Xailer, pero además es un prototipo de lo que después se convertiría en el IDE de Xailer.
El Equipo de Xailer ha decidido mejorarlo y dejarlo como un producto individual independiente de Xailer para ayudar a los programadores novatos en (x)Harbour en los procesos de compilación y enlazado de sus aplicaciones, tanto para modo consola, como para Windows hechas con FiveWin, así es..... puedes usar XEdit para compilar y enlazar tus programas FiveWin. ;-)
Si trabajas con XEdit para migrar tus programas de Clipper a (x)Harbour, posteriormente la migración de tus programas a Windows con Xailer te será mucho mas fácil, ya que XEdit comparte muchas de las características de su hermano mayor: El IDE de Xailer, como son:
El Gestor de Proyectos, El Editor de código fuente, El Depurador visual (solo para aplicaciones modo Consola, no para aplicaciones Windows, la depuración para aplicaciones Windows solo está disponible en Xailer),
El Explorador de DBFs (DBU) y El Editor de SQLite., estos componentes no los voy a explicar en este artículo, pero haz click sobre los enlaces anteriores y obtendrás una descripción detallada de cada uno.
Antes de comenzar debo aclarar que todo lo aquí expuesto está basado en XEdit 5.0.4 de Noviembre 2017, más adelante encontrarás información sobre como obtenerlo.
Bien comencemos.
Los que ya llevamos una temporada trabajando con (x)Harbour sabemos que si bien el compilador es poderoso y versátil, no es nada fácil el proceso de compilación y enlazado de los programas, sobre todo porque tenemos por medio un compilador de C, del cual poco o nada sabemos, y es en este punto es donde el proceso de compilación y enlazado del EXE final se vuelve terrible.
Recordemos como hacíamos un programa EXE en Clipper:
archivo.prg -> archivo.obj -> archivo.exe
Escribimos nuestro código fuente en archivos .PRG, luego con el compilador Clipper compilamos esos archivos .PRG y obtenemos archivos .OBJ, posteriormente tomamos esos archivos .OBJ, y por medio de un enlazador como RTLINK, BLINKER, EXOSPACE etc, uníamos los archivos .OBJ con los archivos de librerías de Clipper (clipper.lib, extend.lib, terminal.lib, dbfntx.lib) y el resultado del proceso de enlazado o "linkeado" era un archivo .EXE.
En (x)Harbour las cosas son "un poquito" mas complejas:
archivo.prg -> archivo.c ->archivo.obj -> archivo.exe
En (x)Harbour tomas tu código fuente en archivos .PRG (el mismo código fuente que tienes en Clipper en este momento, los cambios que tienes que hacer son mínimos), en vez de utilizar el compilador Clipper compilamos con el compilador Harbour (los parámetros de compilación exactamente los mismos que Clipper), pero el resultado de la compilación NO SON ARCHIVOS .OBJ, SON ARCHIVOS ".C", efectivamente, Harbour "traduce" tu código Clipper a código en lenguaje "C", que no es en realidad un código "C" estándar, vamos que si eres experto en "C" y editas el contenido de un archivo resultado de la compilación con Harbour, el código te parecerá mas Ensamblador que "C", esto es porque el código generado es un "PCODE", es decir, un código que solo puede ser interpretado por un motor especial llamado "PMACHINE", la "PMACHINE" para interpretar este PCODE viene en las librerías de Harbour que tienes que enlazar en el archivo .OBJ para generar el archivo .EXE.
Un momento.... entonces sí deben de existir archivos .OBJ en alguna parte del proceso de compilación, ¡ claro que existen !, los archivos .OBJ provienen de compilar el código en "C" para ello necesitas un compilador de C, y aquí es donde empieza la fiesta porque actualmente (x)Harbour es compatible con varios compiladores de "C" como el Microsoft Visual C++ desde la versión 6 hasta la versión 8, el Pelles C, el MingW32 ó el Open Watcom, pero la versión mas popular es la desarrollada para Borland C++, ya que Borland ha liberado al dominio público sin restricciones de uso el compilador Borland C++ Ver. 5.5.
Otra ventaja adicional, es que al generar (x)Harbour código en "C", entonces puedes hacer programas con el lenguaje Clipper que ya conoces para otros sistemas operativos, como Linux, MacOS, OS/2 de IBM, MS-DOS de 32 bits (DR-DOS), eso sí, no serán programas gráficos con ventanas ni nada (Windows forms), serán programas MS-DOS (para modo consola). Para cada uno de estos sistemas operativos existen versiones de (x)Harbour disponibles, obviamente los compiladores de C para estas plataformas son distintos a los usados para aplicaciones Windows.
Retomando el tema, el Compilador de "C" volverá a compilar nuestros archivos generados con (x)Harbour, y ahora sí, generará los archivos .OBJ, posteriormente esos archivos .OBJ hay que "linkearlos" junto con las librerías de (x)Harbour para generar el archivo .EXE final. Todos los compiladores de "C" incluyen su propio enlazador (linker), por lo que no requieres ningún otro producto adicional, así que te puedes olvidar de Blinker, Exospace, etc.
El verdadero problema de generar un EXE con (x)Harbour viene en la parte de proceso de compilación con "C", y es aquí donde XEdit entra en acción.
Así que lo que primero que necesitamos para migrar nuestras aplicaciones es conseguir xHarbour, aunque xEdit soporta compilación con Harbour, también lo puede usar con xHarbour, por otro lado siendo el Borland C++ el compilador de C preferido por los programadores, entonces necesitaremos obtener una versión de xHarbour para Borland C++. Puedes ir directamente a la pagina de
xHarbour.org para descargar la versión para Borland C++.
No hay proceso de instalación, simplemente descarga este archivo .ZIP y desempácalo en una carpeta que se llame de preferencia c:\xharbour (los ejemplos que se mostrarán mas adelante los he construido basándome en esta ubicación).
Luego vas a necesitar el compilador C++ de Borland (ahora Embarcadero Technologies), el uso de este compilador es gratuito, pero no es de libre distribución, tienes que obtenerlo desde la página que Embarcadero ha establecido para tal fin, previo registro. Puedes acceder a la página para obtener el Borland C++ haciendo
click aquí.
El archivo que se descarga se llama FreeCommandLineTools.Exe simplemente ejecútalo y realizará la instalación del compilador en la carpeta c:\Borland.
Finalmente debes descargar la ultima version de XEdit de:
Descarga XEdit desde la web de Xailer
Xedit viene con un programa de instalación con lo cual solo tendrás que ejecutarlo e instalarlo en tu disco duro, no hay nada mas que hacer.
A continuación te explicaré los primeros pasos en el uso de XEdit, que deberán ser suficientes para poder compilar cualquier aplicación Clipper actual a 32 bits con xHarbour.
Ejecuta el archivo XEDIT.EXE desde la carpeta donde lo haz instalado, y procederemos a configurar el comportamiento básico de la herramienta:
Selecciona:
Menú Principal / Herramientas / Opciones Generales
Aparece una ventana como esta:
Esta pantalla solo contiene configuraciones básicas que no te afectarán para tu programa, excepto la opcion que dice "Xailer". No es necesario que tengas Xailer instalado, configura los directorios a donde se encuentre XEdit, si es que el sistema no lo ha hecho por default.
Para poder compilar un programa, necesitamos crear un
entorno de programación. Un entorno de programación es una configuración especial donde le indicaremos a XEdit las carpetas
adicionales y las opciones de los compiladores tanto de xHarbour como de
Borland, necesarias de acuerdo a cada necesidad específica, por ejemplo,
para compilar una aplicación en (x)Harbour para modo consola se
necesitan ciertos parámetros de compilación, mientras que para compilar
una aplicación para Windows hecha con FiveWin, se necesitan incluir
algunas librerías y definir la ubicación de los archivos de cabecera.
Para crear un entorno:
Menú Principal / Herramientas / Entorno de programación.
Puedes tener tantos entornos de programación como necesites, por ejemplo para xHarbour en modo consola, para FiveWin, para Harbour MiniGUI, etc.
Para agregar un nuevo entorno de programación haz click en el botón con el signo "+" que se encuentra en la parte inferior de la plantalla de configuración de entornos:
Lo que sigue es simple, solo tienes que darle un nombre a tu entorno y si lo requieres puedes copiar otro entorno similar para que no tengas que volver a dar todos los datos:
Una vez que haz dado nombre a tu entorno, procederemos a configurarlo con las opciones que muestran los folders de la pantalla de configuración de entorno de programación:
General:
Sirve para indicar las rutas a los archivos INCLUDE y LIB así como los archivos LIB adicionales que necesita tu aplicación.
En el caso de una aplicacion (x)Harbour para modo consola simple y llana, no sera necesario llenar ningun dato de esta pestaña, si tu aplicación es con Harbour MiniGUI o FiveWin, aquí deberás indicar la ruta a donde se encuentran los archivos de cabecera (include) y la ruta a la ubicación de las librerías adicionales que necesite tu aplicación.
Por ultimo para esta pestaña, deberás indicar EL NOMBRE DE LOS ARCHIVOS .LIB que utilice tu programa, EN EL FORMATO DEL COMPILADOR DE C QUE VAYAS A USAR. En el caso del Borland C++ simplemente se indican los nombres de los archivos anteponiendo un signo de "+" y separandolos por comas.
Este es un ejemplo de la configuración para FiveWin:
Compilador xBase:
En esta pestaña configuraremos el compilador de (x)Harbour que deseamos utilizar.
Oficialmente existen 3 versiones actualmente de (x)Harbour, el xHarbour como tal, que como recordarás es un "fork" del proyecto Harbour original, del cual no han hecho muchos cambios ultimamente y 2 versiones de Harbour, la 2.x la 3.x, ¿ Cual es la diferencia ?.
En su momento un grupo de programadores por diferencia de opinión con otros programadores del proyecto Harbour original, decidieron crear su propia versión de Harbour, con miras a crear un producto comercial al que llamaron xHarbour (eXtended Harbour), e incluyeron en el muchas monerias que no encontrarás en Harbour como las estructuras SWITCH, el manejo de archivos XMLs, los "hashes", etc.
Luego vino la gente de Harbour y dijo.... nos estamos quedando atrás y evolucionarion el compilador a la versión 3 incluyendo muchas cosas de lo que xHarbour tenía, optimizando ademas los nucleos y haciendolo mucho mas rapido que xHarbour, además de tener versión de 64 bits, cosa que xHarbour no tiene.
Regresando a nuestro tema, en esta pestaña tendrás que configurar el compilador de (x)Harbour que desees utilizar:
En la parte superior, en los radio botones puedes seleccionar la versión de (x)Harbour que desees usar, y automaticamente en la parte inferior se añadirán las librerias necesarias dependiendo de la versión que vayas a utilizar. Lo unico que tienes que configurar es la ruta donde está tu compilador de (x)Harbour.
TIP: Hay muchas versiones de Harbour, muchas versiones de Xailer o de FiveWin, y en muchas ocasiones hay determinadas versiones del compilador que funcionan con tal o cual versión de otros productos, un consejo práctico: coloca la versión de Harbour compatible con tu herramienta en el mismo directorio donde tienes tu herramienta principal, esto te ahorrará muchos dolores de cabeza en el futuro.
Compilador de C:
(x)Harbour puede usarse con distintos compiladores de C, los mas populares: El Borland C++ porque fue con el que empezó todo y MinGW porque es un compilador de C totalmente open source, le sigue el Pelles C porque es gratuito y compatible con el Microsoft C++.
Quiero hacer aquí un paréntesis para mencionar que aunque no utilices el compilador de C de Pelles C, es conveniente descargarlo porque te ofrece 2 herramientas que si programas en FiveWin o MiniGUI te serán de gran utilidad:
El editor de recursos, que si estas acostumbrado a usar el Borland Resource Workshop y que no funciona en sistemas operativos de 64 bits, lo puede sustituir perfectamente a 32 bits y 64 bits.
El compilador de recursos PORC que además de ser muy rapido, opitimiza perfectamente el ejecutable final.
Puedes descargar el Pelles C haciendo
click aqui
Dependiendo del compilador de C que vayas a utilizar las opciones se cargan automaticamente, solo tienes que establecer la ruta donde se encuentra tu compilador, en este ejemplo he seleccionado el compilador C++ de Borland:
Quedan 2 pestañas por analizar que no utilizaremos en esta primera aproximación a XEdit:
Compilador de recursos: Se utiliza en caso de que quieras usar otro compilador que no sea el del C++ nativo que vayas a usar, por ejemplo el PORC de Pelles C.
Enlazador: Similar a lo anterior, si no quieres usar el enlazador (linker) de tu compilador de C++ puedes usar esta pestaña para configurar otro distinto.
Una vez que hemos creado nuestros entornos de programación, hemos terminado con el proceso de configuración, ahora llegó el momento de comenzar a migrar nuestros programas a 32 bits.
Antes de comenzar, tenemos que entender como trabaja XEdit.
XEdit trabaja en base a "proyectos", un proyecto no es mas que una carpeta del disco duro que a su vez tiene subcarpetas donde se guardan los distintos componentes de la aplicación, por ejemplo el código fuente va en una carpeta, los archivos de cabecera .ch en otra, se hace otra para los archivos de recursos .rc, y así sucesivamente.
Para crear un proyecto nuevo:
Menú principal / Archivo / Nuevo Proyecto....
Puedes crear carpetas nuevas para tus proyectos desde la ventana donde se te pide que le des un nombre al proyecto, personalmente lo que yo hago es crear una carpeta llamada PROYECTOS debajo de la carpeta XEDIT2 y ahí voy creando subcarpetas para guardar cada proyecto.
Creemos pues la capeta "PRUEBA1" y pongamosle el mismo nombre a nuestro proyecto.
La configuración de cada proyecto se guarda en archivos XPJ (Xailer/Xedit ProJect) que no son mas que archivos .XML con información sobre el proyecto que estamos usando.
Pulsamos el botón de ACEPTAR y aparece esta ventana, que configura las propiedades del proyecto:
Aquí indicaremos si queremos crear un EXE, una LIB o una aplicación WEB (de momento no disponible), una descripción del aplicativo que estamos desarrollando, misma que se "pegará" al EXE final, deberemos indicar el nombre del archivo de salida, en este caso prueba1.exe y
MUY IMPORTANTE debemos indicar el ENTORNO DE PROGRAMACION, previamente creado, que vayamos a utilizar para compilar este programa, en este caso "FW xHB", también deberemos indicar el nombre del módulo principal, pero de momento dejaremos en blanco este espacio, presionemos el botón ACEPTAR para guardar los cambios (puedes volver a esta ventana posteriormente desde
Menú Principal / Proyecto / Propiedades del proyecto).
Al presionar el botón Aceptar XEdit te pondrá el siguiente mensaje de aviso:
Indicándote que se van a crear subcarpetas para guardar los distintos componentes de tu aplicación, simplemente haz click en el botón "SI".
Ya estamos listos para hacer un pequeño experimento, vamos a crear un pequeño .PRG de ejemplo y a compilarlo usando xEdit.
Seleccionaremos:
Menu Principal / Archivo / Nuevo / PRG.
Veremos en el editor de código fuente que aparece una pestaña nueva con el nombre MODULE1.PRG, escribiremos lo siguiente y guardaremos este código fuente :
Como verás es un programa Clipper puro y duro, con instrucciones básicas de modo consola.
Llegó el momento de compilar este programa, simplemente selecciona:
Menu Principal / Proyecto / Compilar
ó presiona Ctrl+F9.
Los mensajes del compilador los verás en la parte inferior de la ventana del editor de código:
Si la última línea es 1 Files, X Warnings, 0 Errors .... ¡ Felicidades ! haz logrado compilar tu primer programa a 32 bits.
Para ejecutarlo, haz doble click sobre él en el explorador de Windows y verás aparecer una ventana de MS-DOS con esto:
Para compilar mas de un .PRG, tienes que hacer lo siguiente:
Copia todos los .PRG que vayas a compilar a la carpeta SOURCE, y luego selecciona:
Menu Principal / Proyecto / Añadir Fichero al proyecto
Selecciona todos los .PRGs que necesites, realiza esta misma operación si tienes archivos .CH que desees integrar en tu sistema, estos los deberás colocar en la carpeta INCLUDE de tu proyecto.
Si en alguno de tus programas utilizas una FUNCTION MAIN() entonces en las propiedades del proyecto (Menu principal / Proyecto / Propiedades del Proyecto) en la opción de MODULO PRINCIPAL selecciona el PRG que tiene la función MAIN(), si no tienes función Main en algunos de tus programas, entonces selecciona el .PRG que arranca tu aplicación.
Para compilar todos los programas simplemente presiona Ctrl + F9.
Si estás programando con FiveWin, entonces hay que cambiar algunas cosas y añadir otras:
Los .PRGs para un programa con FiveWin se agregan al proyecto de la misma manera que como se hace para un proyecto para xHarbour modo consola.
Para integrar los recursos gráficos (archivos .RC, .BMP, .ICO, CUR, etc.) al proyecto XEdit, procederemos la siguiente manera:
Primero tenemos que crear un archivo de recursos vacío, esto se hace usando el Gestor de Recursos de XEdit, para activarlo selecciona:
Menu principal / Ver / Gestor de recursos
Y aparecerá la siguiente pantalla:
Presiona el botón que tiene hoja en blanco, del lado izquierdo de la pantalla, ese botón sirve para crear un archivo de recursos .RC vacío, aparecerá una ventana para dar nombre al archivo de recursos, esta pantalla te sugiere el nombre del .RC, en este caso será el mismo nombre que el de tu proyecto, pero mi sugerencia es:
dale el mismo nombre que el archivo .RC que utilizas en tu programa FiveWin, esta operación creará un archivo RC vacío, pero quedará registrado el nombre del RC en las propiedades del proyecto para que al momento de compilar XEdit lo incluya en los archivos que deben ser enlazados para generar el EXE final.
DESPUES de crear el RC vacío, puedes copiar todos tus recursos a la carpeta RESOURCE de tu proyecto XEdit, y XEdit hace el resto, compilará y enlazará los recursos dentro de tu programa .EXE, es MUY IMPORTANTE que primero crees el .RC vacío, ya que si copias primero los recursos a la carpeta RESOURCE y luego creas el .RC con el Gestor de Recursos entonces TE VAS A CARGAR TU .RC, con todos los diálogos, cursores y bitmaps que tenga pegados adentro, así que el que avisa no es traidor, estás advertido.
Aprovechando que estamos hablando del tema de los recursos, la siguiente información te puede ser útil: ¿ sabías que puedes programar XEdit para "lanzar" cualquier aplicación que quieras desde el menú principal ?, esta característica es sumamente útil para enlazar por ejemplo tu editor de recursos como una opción del menú del Xedit, y no tener que ir navegando por todo el disco duro para encontrar el EXE adecuado, yo por ejemplo tengo configuradas las herramientas que más uso la opción HERRAMIENTAS del menú principal:
Para agregar herramientas, que pueden ser no solo archivos .EXE sino también archivos de ayuda .CHM hacemos lo siguiente:
Menu Principal / Herramientas / Configurar Herramientas
Aparece la siguiente pantalla, presiona el boton AÑADIR y luego selecciona el archivo .EXE o .CHM que quieras añadir al menú:
¡ y listo !, haz agregado una herramienta a tu menú, la cual se ejecutará de manera automática cada vez que la selecciones del menú.
Ahora bien, si el compilador de recursos de Borland te está dando problemas con el tamaño de los archivos .RC o con los bitmaps muy grandes o de muchos colores, también puedes cambiar el compilador de recursos para usar otro que dé menos problemas, para saber como lee mi artículo:
Cambiando el compilador de recursos, dentro de este mismo blog, si compilas tu programa FiveWin con XEdit, puedes usar los trucos ahí mencionado, recuerda que XEdit es muy similar al IDE de Xailer.
Retomando el tema de FiveWin con xEdit, otra cosa importante son las librerías adicionales que suelen llevar los programas FW, para empezar las 2 básicas: FIVEHX.LIB y FIVEHC.LIB.
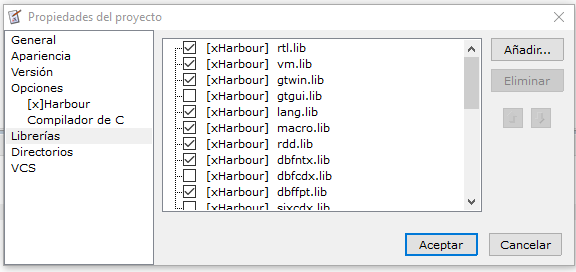
Para la gestión de librerías (archivos .LIB) Xedit posee un gestor de librerías, para acceder a el:
Menú Principal / Proyecto / Propiedades del Proyecto y seleccionar del árbol:LIBRERIAS
Aparece una pantalla similar a esta:
Pulsando el botón AÑADIR, podrás agregar las librerías que quieras incluir en tu proyecto, por default XEdit te incluirá que las de xHarbour y Borland C++, y tu podrás seleccionar las adicionales que necesites haciendo click en el checkbox, en este caso he añadido las 2 librerías de FiveWin. También es posible definir el orden de linkeado, subiendo y bajando las librerías con los botones que tienen flechas.
Existen mas trucos y herramientas disponibles con XEdit, pero ahora te toca a tí descubrirlas. El programador de Clipper que quiera migrar a xHarbour, encontrará en XEdit LA HERRAMIENTA que le facilitará el proceso de migración, además de que si en un futuro decide desarrollar aplicaciones para Windows usando Xailer, pues ya tendrá un buen trecho andado, porque el IDE de Xailer y XEdit comparten muchas herramientas comunes.
El programador de FiveWin también encontrará en XEdit un valioso aliado, conozco muchos programadores que todavía compilan sus programas con archivo .BAT o .MAK desde una ventana de MS-DOS o todavía utilizan el EDIT de MS-DOS o el NOTEPAD para escribir sus programas, con XEdit podrán automatizar mucho de ese trabajo, con el consabido ahorro de tiempo, tendrán un editor de código profesional, así como otras herramientas interesantes todas integradas en un mismo lugar, además de que podrán probar "un poquito" sobre como se desarrolla usando Xailer.
Espero que con este tutorial muchos de ustedes se animen a darle las gracias al nuestro viejo y querido Clipper y que se adentren en el mundo de la programación a 32 bits.